
Alors que les méthodes traditionnelles pour évaluer les performances de l’intelligence artificielle montrent leurs limites, certains développeurs explorent des approches plus créatives. Et quoi de mieux que Minecraft pour cela ?
Un site web original baptisé Minecraft Benchmark (ou MC-Bench) permet ainsi de confronter plusieurs IA à des défis de construction inspirés par des instructions textuelles. Votre rôle ? Observer les créations proposées et voter pour celle qui correspond le mieux à la consigne. Ce n’est qu’après avoir voté que vous découvrez quel modèle a produit quelle construction.
Un projet initié par un lycéen
Derrière ce projet se trouve Adi Singh, élève de terminale, qui voit dans Minecraft bien plus qu’un simple jeu. Pour lui, c’est un langage visuel universel. En tant que jeu le plus vendu au monde, Minecraft est familier à un très large public. Même sans y avoir jamais joué, il est facile de juger si un « ananas en blocs » est bien réalisé ou non.
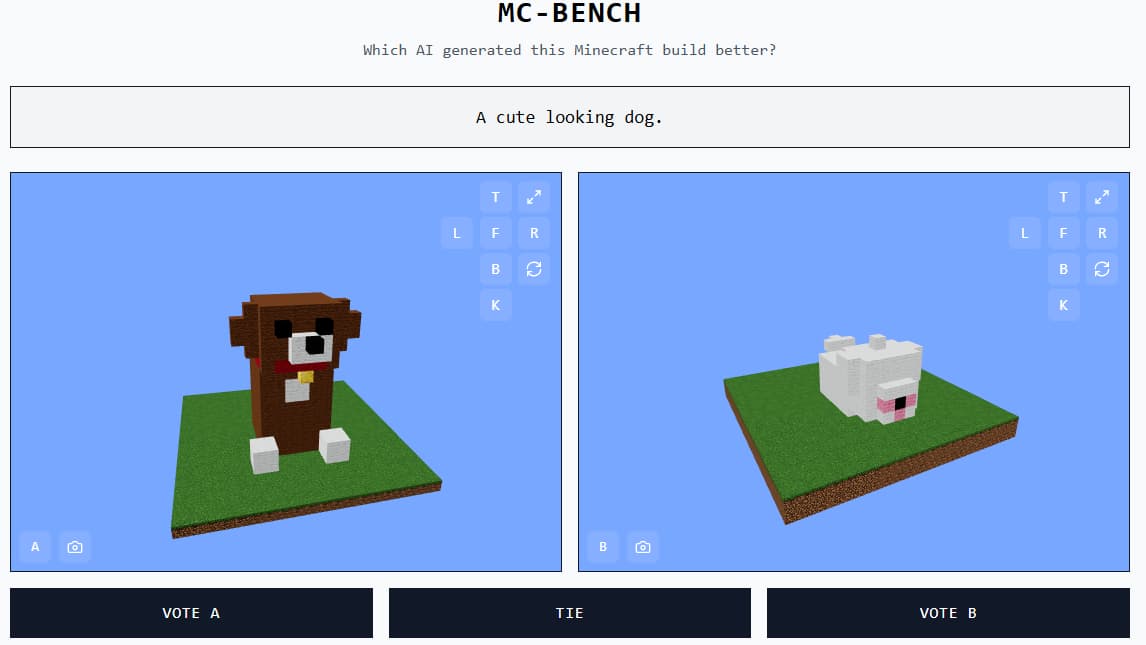
« Minecraft permet de visualiser plus simplement les progrès de l’IA », explique Singh à TechCrunch. « Son esthétique et son ambiance sont déjà connues de tous. »
Actuellement, huit contributeurs bénévoles participent à l’amélioration du site. Des entreprises comme Anthropic, Google, OpenAI et Alibaba soutiennent le projet en mettant à disposition leurs technologies pour exécuter les prompts, sans être directement impliquées dans son développement.

Construire pour mieux évaluer
MC-Bench ne se contente pas de comparer des images : il s’agit en réalité d’un benchmark de programmation, puisque les modèles doivent générer du code pour créer les constructions en jeu. Cela peut aller de simples figures comme Frosty le bonhomme de neige à des scènes plus complexes, comme une cabane tropicale sur une plage immaculée.
Mais au lieu d’analyser des lignes de code, les utilisateurs évaluent les résultats visuellement — ce qui rend l’expérience bien plus accessible. C’est précisément cette accessibilité qui permet à MC-Bench de récolter un grand volume de données sur les performances comparées des IA.
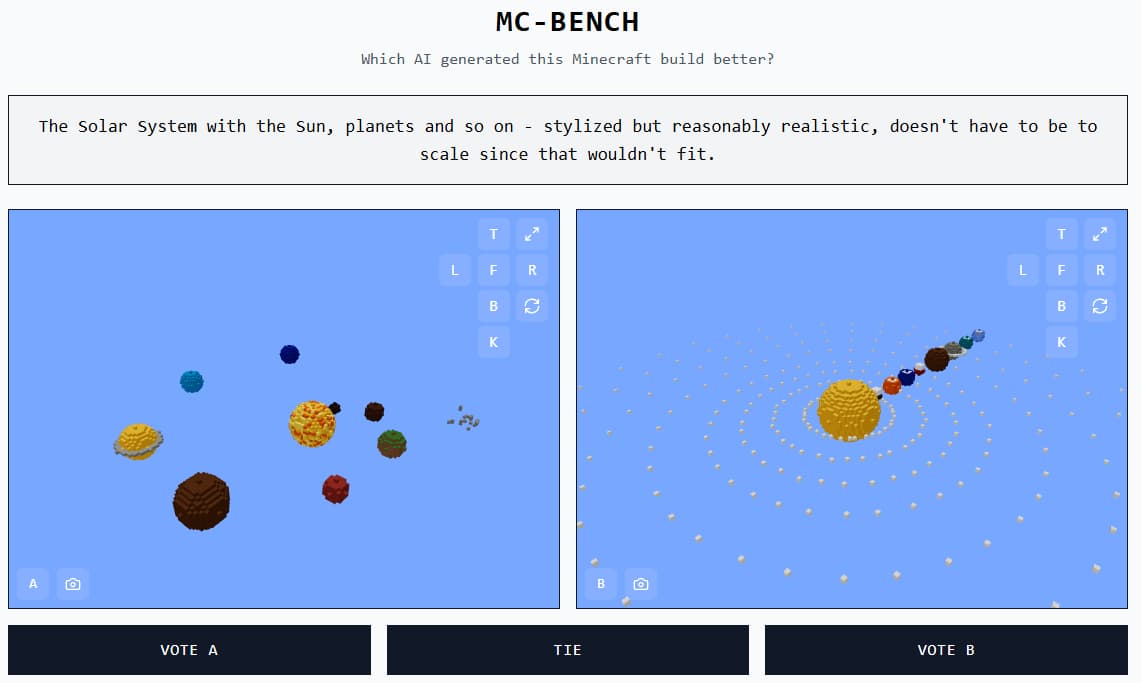
« Pour l’instant, nous nous limitons à des constructions simples, surtout pour observer le chemin parcouru depuis l’époque de GPT-3 », précise Singh. « Mais à terme, nous pourrions imaginer des tâches plus longues, avec des objectifs à atteindre. Les jeux vidéo pourraient bien être un terrain d’essai idéal pour le raisonnement autonome, à la fois plus sûr et plus contrôlable que dans le monde réel. »
L’art complexe du benchmarking
Et justement, les premiers résultats obtenus sur MC-Bench sont parlants. Le classement repose sur un système de score ELO, calculé à partir de milliers de votes anonymes où chaque IA est jugée à l’aveugle, uniquement sur la qualité visuelle de ses constructions.
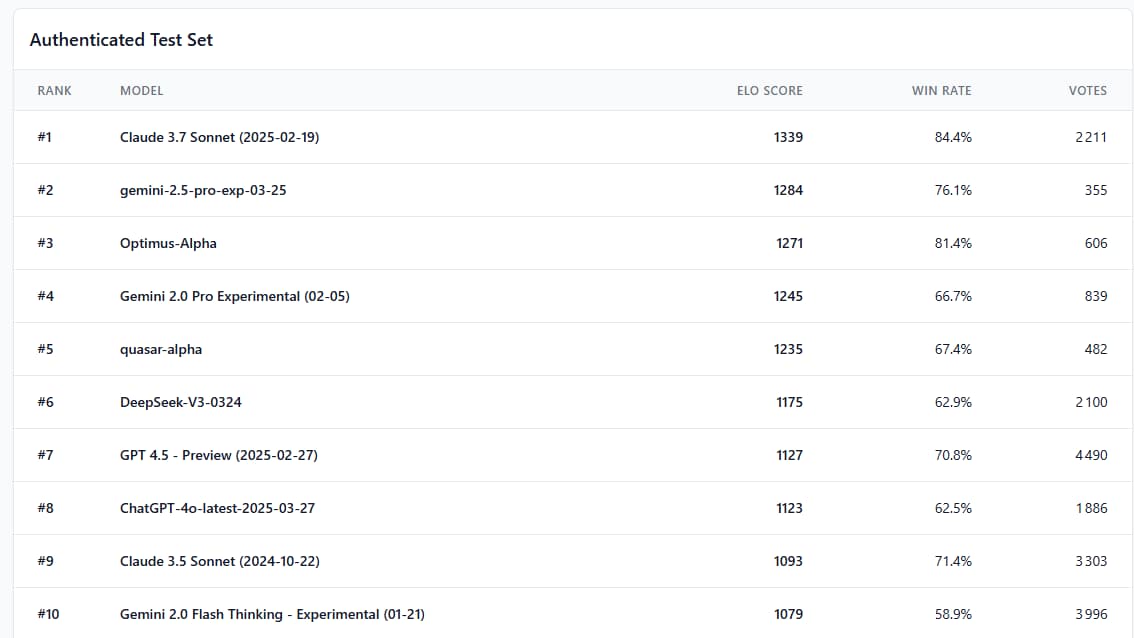
En tête de ce palmarès : Claude 3.7 Sonnet, avec un score de 1339 et un taux de victoire impressionnant de 84,4 %. Il devance nettement Gemini 2.5 Pro Experimental (1284 points, 76,1 %) et Optimus-Alpha (1271 points, 81,4 %). À l’inverse, la dernière version de ChatGPT, baptisée GPT-4o (mars 2025), n’arrive qu’en 8ᵉ position avec un score de 1123 et un taux de victoire de 62,5 %, derrière son propre prédécesseur GPT-4.5 Preview (70,8 %). Même Claude 3.5 Sonnet, plus ancien, fait mieux.
Ces résultats, bien qu’expérimentaux, dessinent une cartographie inattendue du paysage actuel des IA génératives : certains modèles très performants en traitement du langage échouent à transformer des instructions simples en créations visuelles cohérentes dans Minecraft.
« Le classement actuel reflète assez fidèlement mon ressenti personnel sur ces modèles », affirme-t-il. « Contrairement à d’autres benchmarks textuels, celui-ci pourrait vraiment aider à savoir si une entreprise va dans la bonne direction. »











Incroyable ! Franchement bonne idée d’utiliser un ensemble d’instruction de code simple plutôt que de générer un schematic. Hâte de voir si les éditeur IA vont réellement utiliser ce projet pour améliorer leur IA sur l’aspect interprétation visuel 3D. Pas sur que les IA LLM soit les plus adapté, ça pourra donné naissance à un nouveau type d’IA spécialisé dans la conception 3D (from text/image/video)